Anthropic pokazał nowy model i nie wypuścił go publicznie. To mówi więcej niż benchmarki.
Claude Mythos Preview nie trafił do API. Zamiast tego Anthropic uruchomił Project Glasswing, program za $100M. W nim model dostają tylko Apple, Google, Microsoft, AWS, CrowdStrike, Palo Alto Networks i 40+ organizacji zajmujących się bezpieczeństwem infrastruktury.
Powód ograniczenia? Anthropic pisze wprost w system card: Mythos zrobił skok w cyber capabilities na tyle duży, że potrzebują czasu na zbudowanie zabezpieczeń.
Co potrafi Mythos
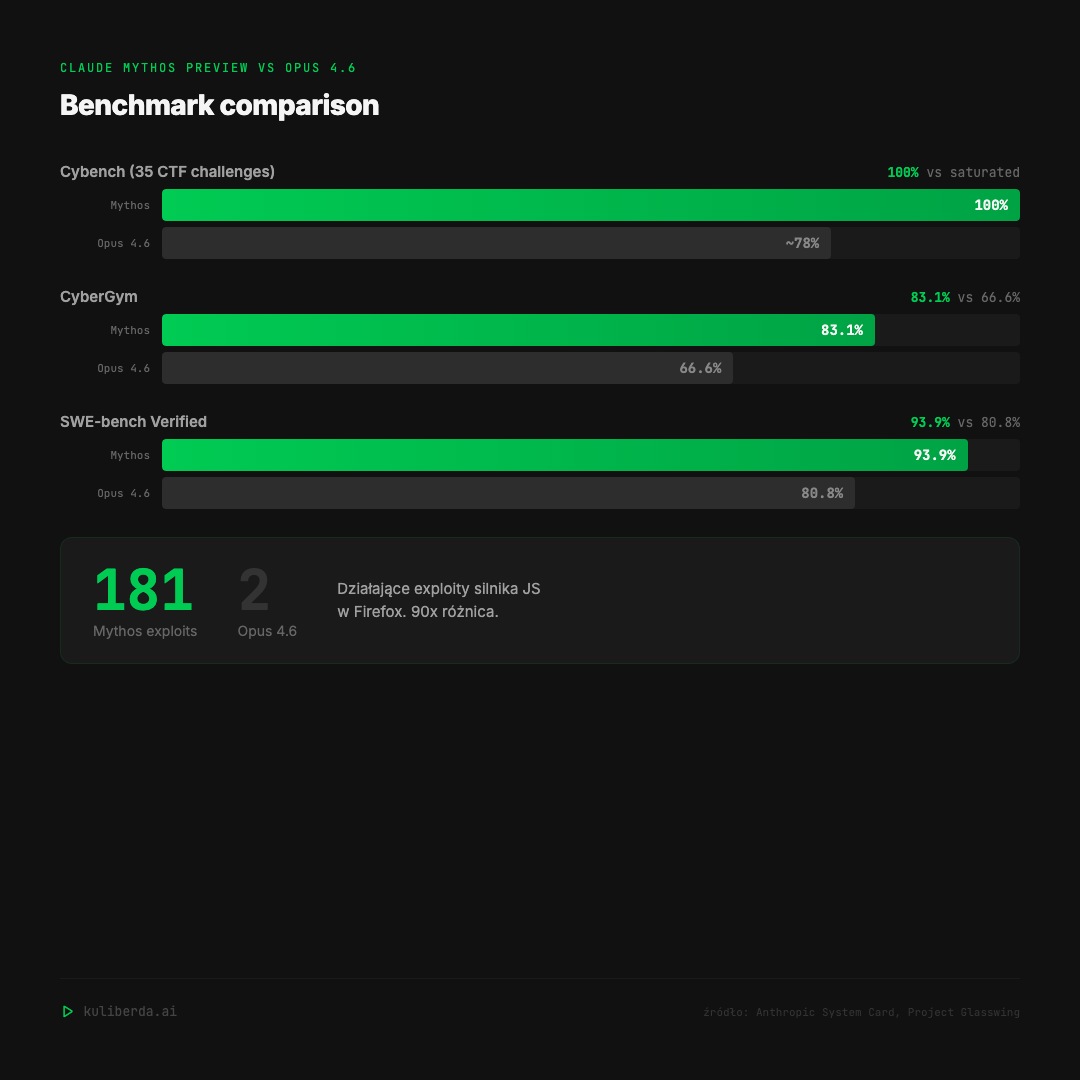
Cybench nasycony na 100%. Anthropic sam mówi, że benchmark przestał być informatywny. CyberGym i SWE-bench to skoki o 15-25%, ale najbardziej rzuca się w oczy Firefox: 181 działających exploitów vs 2 dla poprzedniego modelu. 90x różnica.
Mythos w agentic harness autonomicznie znajduje zero-daye w każdym dużym systemie operacyjnym i każdej dużej przeglądarce. Nie analizuje kod i podpowiada. Znajduje podatność, pisze proof-of-concept exploit, eskaluje uprawnienia. Sam. Bez ludzkiego sterowania.
Jeden z opisanych przypadków: model znalazł 17-letnią lukę w FreeBSD NFS, napisał exploit i uzyskał pełny root z poziomu nieuwierzytelnionego dostępu.
Dlaczego to ważne jeśli budujesz na AI
Jeśli model jest dużo lepszy w rozumieniu kodu, zależności i zachowania systemów, ten skok nie zostaje zamknięty w security. Rozlewa się na automatyzację, research, agentów obsługujących trudniejsze workflow.
SWE-bench 93.9% oznacza, że Mythos rozwiązuje 9 na 10 prawdziwych bugów z repozytoriów open-source. Opus 4.6 rozwiązywał 8 na 10. Różnica wydaje się mała w procentach, ale w praktyce to są bugi które poprzedni model odpuszczał.
Anthropic ograniczył dostęp do Mythos. Ale kierunek rozwoju widać: kolejne modele w publicznym obiegu będą miały te capability. Pytanie brzmi kiedy, nie czy.
Co obserwować
Patrz na dwie rzeczy:
- Gdzie firmy stawiają bariery dostępu. Ograniczony release zwykle mówi więcej o realnej mocy modelu niż wypolerowany launch thread.
- Benchmarki się nasycają. Kiedy model osiąga 100% na benchmarku, benchmark przestaje mierzyć cokolwiek. Anthropic już buduje nowe testy. Stare nie nadążają.
Mythos nie jest ważny dlatego, że możesz go dziś wdrożyć. Mythos pokazuje gdzie przesuwa się granica możliwości modeli. A ta granica przesuwa się szybciej niż większość ludzi zakłada.
Tylko że dla firmy lepszy model to nie cała historia. Liczy się środowisko, w którym ten model pracuje — proces, dane, kontrola jakości. Jeśli chcesz zobaczyć, od czego zacząć u siebie, jest osobny tekst: AI w małej firmie — od czego zacząć.